
使用ツール:Visual Studio Community 2019
使用言語 :C言語
配列とポインタ
配列は同じ型のデータを連続的にメモリ上に配置したもので、下記の様に宣言します。
int arr[10]; // int型配列(スタック領域)
これで10個分のint型のデータを扱える様になります。
ポインタはデータのメモリ上のアドレスを格納する変数です。
int* ptr; // int型ポインタ ptr = &arr[0]; // 配列の最初の要素が格納されているアドレス
『ポインタは苦手』と言う話も良く聞きますが、メモリ配置を理解していれば、それほど難しいものではないと思います。
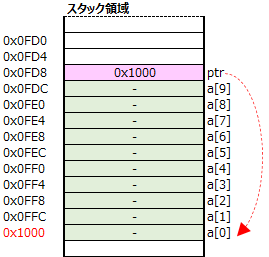
関数内で配列を宣言する場合の注意
関数内で宣言した場合は、配列用のメモリはスタック領域に確保されますが、スタック領域のデフォルトのサイズは1MBなので、それを超えるような大きな要素数の配列を宣言すると、コンパイルは出来ますが、実行時にスタック・オーバーフローを起こし、エラー終了してしまいますので、ご注意ください。
ただし、コンソールでcl.exeで作成したプログラムは、実行時エラーが起きても特に何もエラーメッセージは出さず終了してしまいます。
エラー終了したかは、下記の様にエラーコード(ERRORLEVEL)を確認するする事になります。
C:\Test\LLP_005>echo %ERRORLEVEL%
-1073741571-1073741571を16進数に変換すると、以下の様に「0xC00000FD」となります。

これは、スタックオーバーフローを示すエラーコードになります。
大きなサイズの配列は、ヒープ領域を使用する必要があります。(mallocで確保、freeで解放)
サンプルコード
今回使用するC言語のサンプルコードは下記です。
#include <stdio.h>
#include <stdlib.h>
#define ARR_SIZE 10000 // 配列サイズ
void main()
{
int arr[ARR_SIZE]; // int型配列(スタック領域)
int *ptr; // int型ポインタ
int *endptr;
long sum1, sum2;
// 配列を初期化(乱数を格納)
for(int i = 0;i < ARR_SIZE; i++)
{
arr[i] = rand();
}
// 配列要素を指定して総和を計算
sum1 = 0;
for(int i = 0; i < ARR_SIZE; i++)
{
sum1 += arr[i];
}
// ポインタを利用して総和を計算(その1)
sum2 = 0;
ptr = &arr[0];
for(int i = 0; i < ARR_SIZE; i++)
{
sum2 += *ptr++;
}
printf("sum1 = %ld\nsum2 = %ld\n", sum1, sum2);
}13~17行目は配列要素を乱数を使って配列要素を初期化しています。
19~24行目は配列の全要素の総和をfor配列のインデックスを使用して求めています。
26~32行目は配列の全要素の総和をポインタを使用して求めています。
34行目はそれぞれで求めた総和を出力しています。(いずれも同じ値になる事を確認するためです)
アセンブリコード
「cl.exe /FA sample_005_1.c」を実行することで、アセンブリコード(sample_005_1.asm)が今回からは、全コードは長くなりすぎるので、一部だけ抜き出していきます。
Cソースの20~24行目に当たる部分は下記になります。
; Line 20 mov DWORD PTR _sum1$[ebp], 0 ; Line 21 mov DWORD PTR _i$2[ebp], 0 jmp SHORT $LN7@main $LN5@main: mov edx, DWORD PTR _i$2[ebp] add edx, 1 mov DWORD PTR _i$2[ebp], edx $LN7@main: cmp DWORD PTR _i$2[ebp], 1000 ; 000003e8H jge SHORT $LN6@main ; Line 23 mov eax, DWORD PTR _i$2[ebp] mov ecx, DWORD PTR _sum1$[ebp] add ecx, DWORD PTR _arr$[ebp+eax*4] mov DWORD PTR _sum1$[ebp], ecx ; Line 24 jmp SHORT $LN5@main $LN6@main:
84~87行の4命令が「sum1 += arr[i];」に当たる部分で、それ以外はsum1の初期化とforループに関する処理です。
「sum1 += arr[i];」の部分は下記の様な事を行っています。
- インデクスiの値をレジスタAXに格納
- 総和sum1の値をレジスタCXに格納
- レジスタCXの値にarr[i]の値を加算(intのサイズが4なので、アドレスはBP + i *4となる)
- レジスタCXの加算結果を総和sumに格納
Cソースの27~32行目に当たる部分は下記になります。
; Line 27 mov DWORD PTR _sum2$[ebp], 0 ; Line 28 mov edx, 4 imul eax, edx, 0 lea ecx, DWORD PTR _arr$[ebp+eax] mov DWORD PTR _ptr$[ebp], ecx ; Line 29 mov DWORD PTR _i$1[ebp], 0 jmp SHORT $LN10@main $LN8@main: mov edx, DWORD PTR _i$1[ebp] add edx, 1 mov DWORD PTR _i$1[ebp], edx $LN10@main: cmp DWORD PTR _i$1[ebp], 1000 ; 000003e8H jge SHORT $LN9@main ; Line 31 mov eax, DWORD PTR _ptr$[ebp] mov ecx, DWORD PTR _sum2$[ebp] add ecx, DWORD PTR [eax] mov DWORD PTR _sum2$[ebp], ecx mov edx, DWORD PTR _ptr$[ebp] add edx, 4 mov DWORD PTR _ptr$[ebp], edx ; Line 32 jmp SHORT $LN8@main $LN9@main:
108~115行の7命令が「sum1 += +ptr++;」に当たる部分で、92行目がsum2の初期化、94~97行目がポインタptrの初期化、それ以外がforループに関する処理です。
「sum1 += *ptr++;」の部分は下記の様な事を行っています。
- ポインタptrの値(アドレス)をレジスタAXに格納
- 総和sum2の値をレジスタCXに格納
- レジスタCXの値にポインタptrが指し示すアドレスの値を加算
- レジスタCXの値を総和sum2に格納
- ポインタptrの値(アドレス)をレジスタDXに格納
- レジスタDXの値に4(intのサイズ)を格納
- レジスタDXの値をポインタptrに格納
配列のインデックスを利用する場合より、ポインタを利用する場合の方が命令数が3つ多いですが、これはポインタ変数のインクリメント「ptr++」を実行している部分になります。
「じゃあ、ポインタを使う方が時間が掛かるのでは?」とも思いますね…。
処理時間の確認
配列を使った場合の処理時間とポインタを使った場合の処理時間を計測したいのですが、前回同様計測したいコード量(命令量)に対して、forループのコード量(命令量)が多いので、配列操作かポインタ操作の処理時間の差が出てこない可能性がありますが、通常利用する場合もforループなどのループ処理が必要になるので、今回は下記の様な計測コードを作成しました。
#include <stdio.h>
#include <stdlib.h>
#include <windows.h>
#define ARR_SIZE 10000 // 配列サイズ
#define LOOP_NUM 100000 // ループ数
void main()
{
int arr[ARR_SIZE]; // int型配列(スタック領域)
int *ptr; // int型ポインタ
long sum1, sum2;
long time0, time1, time2;
// 配列を初期化(乱数を格納)
for(int i = 0;i < ARR_SIZE; i++)
{
arr[i] = rand();
}
time0 = GetTickCount();
// 配列要素を指定して総和を計算
for(int j = 0; j < LOOP_NUM; j++)
{
sum1 = 0;
for(int i = 0; i < ARR_SIZE; i++)
{
sum1 += arr[i];
}
}
time1 = GetTickCount();
// ポインタを利用して総和を計算(その1)
for(int j = 0; j < LOOP_NUM; j++)
{
sum2 = 0;
ptr = &arr[0];
for(int i = 0; i < ARR_SIZE; i++)
{
sum2 += *ptr++;
}
}
time2 = GetTickCount();
//各方法での総和の確認
printf("sum1 = %ld\nsum2 = %ld\n", sum1, sum2);
//各方法での処理時間の確認
printf("t1 = %ld\nt2 = %ld\n", time1 - time0, time2 - time1); //
}内容は先ほどのコードの各処理に更にforループで囲み処理回数を稼いでいます。(処理がすぐに終わってしまうと、計測ができないためです)
さて、このコードをコンパイルして、実行してみると下記の様になります。
C:\Test\LLP_005>sample_005_2.exe
sum1 = 165075799
sum2 = 165075799
t1 = 2438
t2 = 2187
C:\Test\LLP_005>t1が配列をインデックスを使ってアクセスする際の処理時間で、t2がポインタを利用した場合の処理時間です。
ポインタを利用する方がアセンブリコードの命令数が多くなっていたのに、処理時間は1割ほど短くなっています。
色々実験してみると、配列をインデックスを指定してアクセスする場合(例:arr[0]やarr[i]など)は、同じ1命令でも通常の変数のアクセスよりは数倍の時間が掛かる様です。
時間が掛かると言っても、少ない回数のアクセスであれば、アッと言う間に処理は完了してしまうので、違いはほとんど分からない場合が多いと思います。
ただ、巨大なデータを扱う際に、ちょっとでも早く処理したいと思えば、ポインタを使う事も選択肢に入るかも知れません。
ちなみに、もう少しだけ処理時間を短く使用とした場合、下記の様なコードも考えられます。
endptr = &arr[ARR_SIZE];
for(int* p = &arr[0]; p < endptr; p++)
{
sum2 += *p;
}ポインタには配列要素を示すインデックス「i」は不要なので、forループ内容を変化させています。
ただ、速度を求めすぎると、コードに問題が発生した時に、デバッグが困難になります。
インデックス「i」があれば、何番目の要素で問題になったかを「i」の値を調べればわかりますが、それを除いてしまうと分からなくなります。デバッグのために別途要素数を調べるためのインデックス「i」を追加するというような事をすると、結局時間の掛かるコードになってしまいます…。
今回のまとめ
今回は、配列とポインタについて、主に処理時間について確認してみました。
ポインタを使った方が、配列+インデクスを使う場合より、命令数は多くなりますが、処理時間は短くなりました。
処理時間の目安に、アセンブリコードの命令数を利用することもできますが、そうでない場合もある事を確認出来ました。
各CPUメーカーのスペックやデベロップメントマニュアルなどを調べれば、どの命令にどれだけ時間が掛かるかが分かるかも知れませんが、命令数は膨大なのであまり現実的ではありません…。
色々な方法でコードを書いて、実際に動かして、そういった経験値も必要ではないかと思います。
また、個人的な意見ですが、『コードの高速化(処理時間の短縮化)もほどほどに』『メンテナンス性を下げない様にある程度の可読性は残しておく』という事も大切だと思います。
次回の予定
次回は条件分岐処理について確認していこうと思います。
(forループに既に、条件分岐は含まれてしまっていますが…)
| 前の記事 | 次の記事 |
|---|---|
| No.04 : 関数について | No.06:条件分岐 |