
使用ツール:Visual Studio Community 2019
使用言語 :C言語
関数について
C言語では「関数」と読んだり、他の言語では「メソッド」と読んだりしますが、特定の処理をひとまとめにして、色んな場所から呼び出す事が出来るようにしたものです。
サンプルコード
今回利用するサンプルコードは下記の様なものです。
#include <stdio.h>
int plus(int x, int y)
{
return (x + y);
}
void main()
{
int a = 1;
int b = 2;
int c = plus(a, b); // 関数呼び出し
}説明の必要もないかも知れませんが、3~6行目の関数pulus()は引数x、yを受け取って、x+yの計算結果を戻り値として返します。
13行目では、前回確認したコードの「c=a+b」の「a + b」の部分をplus関数に置き換えています。
今回は、このコードがどのように動作するかをアセンブリコードレベルで確認していきます。
アセンブリコード
「cl.exe /FA sample_002.c」を実行し、アセンブリコード(sample_002.asm)を生成すると下記の様になります。
; Listing generated by Microsoft (R) Optimizing Compiler Version 19.29.30146.0 TITLE C:\Test\LLP_004\sample_002.obj .686P .XMM include listing.inc .model flat INCLUDELIB LIBCMT INCLUDELIB OLDNAMES PUBLIC _plus PUBLIC _main ; Function compile flags: /Odtp _TEXT SEGMENT _c$ = -12 ; size = 4 _a$ = -8 ; size = 4 _b$ = -4 ; size = 4 _main PROC ; File C:\Test\LLP_004\sample_002.c ; Line 9 push ebp mov ebp, esp sub esp, 12 ; 0000000cH ; Line 10 mov DWORD PTR _a$[ebp], 1 ; Line 11 mov DWORD PTR _b$[ebp], 2 ; Line 13 mov eax, DWORD PTR _b$[ebp] push eax mov ecx, DWORD PTR _a$[ebp] push ecx call _plus add esp, 8 mov DWORD PTR _c$[ebp], eax ; Line 14 xor eax, eax mov esp, ebp pop ebp ret 0 _main ENDP _TEXT ENDS ; Function compile flags: /Odtp _TEXT SEGMENT _x$ = 8 ; size = 4 _y$ = 12 ; size = 4 _plus PROC ; File C:\Test\LLP_004\sample_002.c ; Line 4 push ebp mov ebp, esp ; Line 5 mov eax, DWORD PTR _x$[ebp] add eax, DWORD PTR _y$[ebp] ; Line 6 pop ebp ret 0 _plus ENDP _TEXT ENDS END
20~43行目がmain関数、44~60行目がplus関数になります。
16~18行目に、main関数で利用する変数a,b,cの格納場所について記載がありますが、前回とはa, bが入れ替わっていますが、スタック領域の格納位置が入れ替わっているだけですので、動作に影響はありません。
C言語のmain関数とplus関数の位置もアセンブリコードでは逆になっていますが、これも動作には影響はありません。
アセンブリコードの確認
アセンブリコードがどの様に実行されていくのかを確認していきます。
main関数の確認(plus関数呼び出しまで)
main関数部分のアセンブリコードを確認していきますが、main関数の下記のC言語ソースの11行目までは前回と同じなので、今回は割愛します。
void main()
{
int a = 1;
int b = 2;スタック領域は下記の様になります。
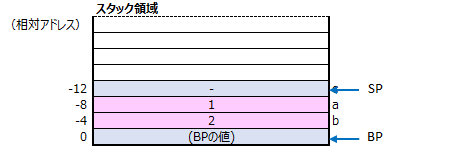
int c = plus(a, b);
main関数からplus関数を呼び出す部分になります。
; Line 13 mov eax, DWORD PTR _b$[ebp] push eax mov ecx, DWORD PTR _a$[ebp] push ecx call _plus
30、31行目はmovコマンドで変数bの値をaxレジスタにコピーした後、それをpushコマンドでスタックに積んでいます。
同じ様に32、33行目は変数aの値をcxにコピーした後、それをスタックに積んでいます。
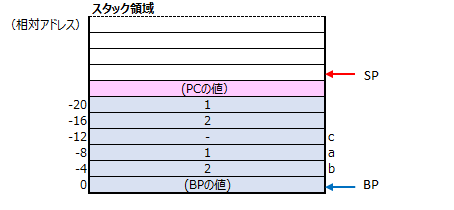
この部分は、plus関数の引数をスタックに積んでいる処理になり、スタックは下記の様な状態になります。

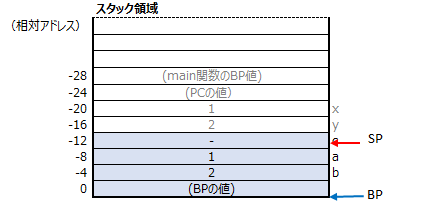
34行目では、callコマンドでplus関数(アセンブリコードで関数と呼ぶのが正しいかは不明ですが…)を呼び出す部分になります。この中では以下の様な事が行われています。
- 現在のPC(プログラムカウンタ)のスタック領域への退避
plus関数へ処理を映すという事は、PC(プログラムカウンタ)の値をplus関数のコードの位置へ変更する事になりますが、plus関数が終了した後、呼び出す前の次の処理に移るためにPCの値を保存しておく必要があります。
- PC(プログラムカウンタ)をplus関数のコード位置へ変更
plus関数のコードを実行するために、PCの値をplus関数の先頭へ変更します。
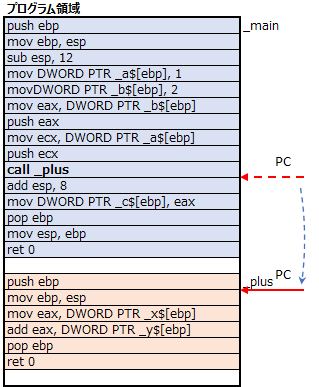
これで、処理は一旦メイン関数を離れ、plus関数へ処理へ移ります。
plus関数のアセンブリコードの確認
plus関数部分のアセンブリコードを確認いていきます。
_x$ = 8 ; size = 4 _y$ = 12 ; size = 4
この部分は、引数x, yのスタック領域におけるBP(ベースポインタ)からの相対位置を示しています。main関数の場合、この値は-(マイナス)の値でしたが、関数の引数や、関数内で利用される引数では+(プラス)の値になります。これは、BP(ベースポインタ)の位置関係によるものです。
; Line 4 push ebp mov ebp, esp
関数のはじめ(51行目)、呼び出し側のmain関数で利用してたBPの値をpush命令でスタックに積んでいます。
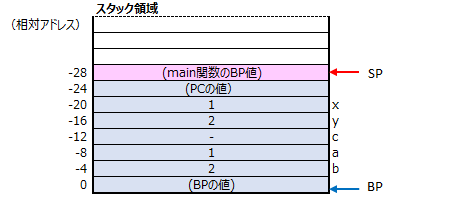
そして、52行目で現在のSPの値をBPに格納して、BPの位置を更新しています。
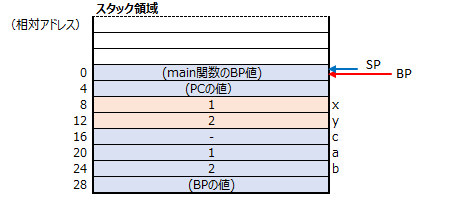
BPが更新された事で、plus関数の引数x, yへのアクセス(相対アドレスでのアクセス)が出来る様になりました。
return (x + y);
引数x, yの値を加算して、戻り値にする処理は下記の様なアセンブリコードになります。
; Line 5 mov eax, DWORD PTR _x$[ebp] add eax, DWORD PTR _y$[ebp]
54行目では、movコマンドで引数xの値をaxレジスタに格納しています。

55行目では、addコマンドで、axレジスタの値と引数yの値を加算し、結果をaxレジスタに格納しています。

関数の戻り値はaxレジスタへ格納する決まりなので、追加のコマンドは必要がありません。
; Line 6 pop ebp ret 0 _plus ENDP
plus関数の終了処理で下記を行います。
57行目で、popコマンドで、スタック領域に格納していたmain関数のBP値を取り出し、BPを更新します。
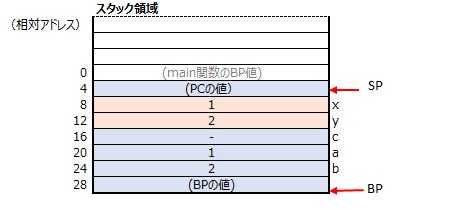
58行目では、retコマンドでは、スタック領域からmain関数からplus関数をcallした際の値を取得し、PCを更新します。
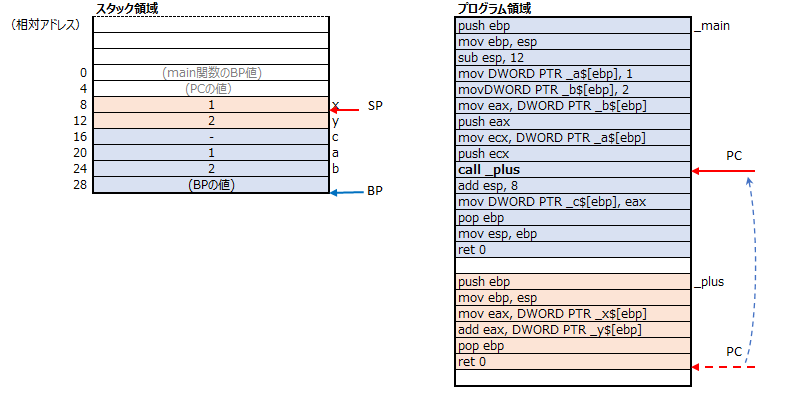
以上で、plus関数の処理は終わり、処理はmain関数に移ります。
main関数の確認(plus関数呼び出し後)
add esp, 8
35行目は、SPに8を加えて、SPを更新します。(「8」はplus関数の引数用にint(size=4)を2個分利用していたので、それを解放するためですので、この値はプログラムによって変化します)
この処理で、スタック領域、BP、SPがplus関数呼び出し前の状態に戻りました。
mov DWORD PTR _c$[ebp], eax
36行目では、movコマンドにより、plus関数の戻り値が格納されているaxレジスタの値を、変数cへ格納します。

これで、c=plus(a, b);の処理が終了しました。
main関数の終わりの部分の処理は、前回と同じなので、説明は割愛します。
関数呼び出しのオーバーヘッド
関数呼び出しに必要な処理
関数を呼び出す場合に下記の処理が必要になります。
- 関数の引数をpushコマンドでスタック領域に格納
- PCをスタック領域に格納
- PCを呼び出し先アドレスへ変更
- BPをpushコマンドでスタック領域に格納
- popコマンドでBPを復元
- PCをスタック領域から呼び出し復元
- SPの位置を復元
これらの分が必ず関数呼び出しに必要となるので、その分オーバーヘッドとなります。
オーバヘッドと言っても処理は、ごく短時間で完了するので、通常は気にする必要はない程度ですが。
実際の例
前回は、2つの変数a(=1), b(=2)の和を「+」演算子を利用して計算し、今回は自作のplus関数を利用して計算しました。
両方とも同じ結果c(=3)になりますが、それに至る処理が異なりました。
「c = a + b;」の場合は、下記の様に3命令で置き換えられていました。
mov eax, DWORD PTR _a$[ebp] add eax, DWORD PTR _b$[ebp] mov DWORD PTR _c$[ebp], eax
「c = plus(a, b);」の場合は、下記の様に13命令で置き換えられていました。(plus関数部分をmain関数内に埋め込んだような形にしています)
mov eax, DWORD PTR _b$[ebp]
push eax
mov ecx, DWORD PTR _a$[ebp]
push ecx
call _plus
; _plus START
push ebp
mov ebp, esp
mov eax, DWORD PTR _x$[ebp]
add eax, DWORD PTR _y$[ebp]
pop ebp
ret 0
; _plus END
add esp, 8
mov DWORD PTR _c$[ebp], eax同じ簡単な計算ですが、関数を呼び出しで実装すると、そうでない場合に比べて10命令分多く、およそ4倍の命令数になっていますので、それだけ処理に時間が掛かる事を意味しています。
処理時間の比較
実際にどれだけ差が生じるかを、実際に計測を行ってみたいと思います。
間違った計測コード
現在のPCでは数命令などはアッと言う間に処理してしまうので、時間を計測しようとした時、以下の様な繰り返し処理を使ったコードを考えると思います。
#include <stdio.h>
#include <windows.h>
#define LOOP_NUM 100000000 // 繰り返し回数:1億回
int plus(int x, int y)
{
return (x + y);
}
void main()
{
int a = 1;
int b = 2;
int c = 0;
long t0, t1, t2;
// "+"を使った処理の処理時間
t0 = GetTickCount();
for (long i = 0; i < LOOP_NUM; i++)
{
c = a + b;
}
t1 = GetTickCount() - t0;
// "+"を使った処理の処理時間
t0 = GetTickCount();
for (long i = 0; i < LOOP_NUM; i++)
{
c = plus(a, b);
}
t2 = GetTickCount() - t0;
printf("処理時間(+) :%ld (ms)\n", t1);
printf("処理時間(plus()):%ld (ms) [%.2f%%]\n", t2, (float)t2 * 100 / t1);
}計測には、GetTickCount()を利用しますが、これは1msの解像度しかないので、forループで1億回回しています。
その処理結果は・・・
C:\Test\LLP_004>sample_003.exe
処理時間(+) :219 (ms)
処理時間(plus()):297 (ms) [135.62%]う~ん、確かに関数呼び出しの方が時間は掛かってるけど、何倍も変わるほどでは・・・と思いたくなりますが、これは、計測対象の処理が軽すぎるので、計測に使っているforループの処理の比率が大きくなって、それを含めた処理時間の計測になってしまっているためです。
例えば、「c=a+b」をforループで回している部分のアセンブリコードは下記の様になっています。
; Line 21 mov DWORD PTR _i$2[ebp], 0 jmp SHORT $LN4@main $LN2@main: mov eax, DWORD PTR _i$2[ebp] add eax, 1 mov DWORD PTR _i$2[ebp], eax $LN4@main: cmp DWORD PTR _i$2[ebp], 100000000 ; 05f5e100H jge SHORT $LN3@main ; Line 23 mov ecx, DWORD PTR _a$[ebp] ; 計測対象コード add ecx, DWORD PTR _b$[ebp] ; 計測対象コード mov DWORD PTR _c$[ebp], ecx ; 計測対象コード ; Line 24 jmp SHORT $LN2@main $LN3@main:
計測対象が3命令なのに、forループ関連のコードが8命令も余分に追加されてしまっていますので、11命令分を計測している事になっています。
「c = plus(a, b)」の場合13命令で構成されていたので、21命令分を計測している事になります。
命令数の比較では、1.9倍程度になる計算ですが、1命令が必ず1クロックで完了するとは限らないので、実際にはこれより値は小さくなるでしょう…。
修正した計測コード
forループなどを使わずに繰り返しを実装する事は難しいので、出来るだけforループの影響を小さくするために下記の様なコードで計測します。
#include <stdio.h>
#include <windows.h>
#define LOOP_NUM 1000000 // 繰り返し回数:100万回
int plus(int x, int y)
{
return (x + y);
}
void main()
{
int a = 1;
int b = 2;
int c = 0;
long t0, t1, t2;
// "+"を使った処理の処理時間
t0 = GetTickCount();
for (long i = 0; i < LOOP_NUM; i++)
{
c = a + b;
c = a + b;
// ...
// 100回書き下す
// ...
c = a + b;
c = a + b;
}
t1 = GetTickCount() - t0;
// "+"を使った処理の処理時間
t0 = GetTickCount();
for (long i = 0; i < LOOP_NUM; i++)
{
c = plus(a, b);
c = plus(a, b);
// ...
// 100回書き下す
// ...
c = plus(a, b);
c = plus(a, b);
}
t2 = GetTickCount() - t0;
printf("処理時間(+) :%ld (ms)\n", t1);
printf("処理時間(plus()):%ld (ms) [%.2f%%]\n", t2, (float)t2 * 100 / t1);
}forループの影響を少なくするために、ループ内に100個同じコードを書き下し、ループの回数を1/100の100万回にしています。
これを実行すると…
C:\Test\LLP_004>sample_004.exe
処理時間(+) :32 (ms)
処理時間(plus()):250 (ms) [781.25%]この結果を見ると、「c=a+b;」の処理は、「c = plus(a, b);」の処理より、約1/7程度になると分かります。(計測の度に若干変動はしますが)
関数呼び出しで利用されるpushやpopなどは1命令で数クロック利用するため、命令数の比較の予測の約1/4より、更に小さくなっているのでしょう。
※「c = plus(a, b);」の処理も変わらず1億回ですが、処理1/10程度に短縮しているのも注目ですね。
少し補足
上記の計測コードで、最初に示したコードを「間違ったコード」と紹介していますが、”間違った”というのは、「計測方法として間違えている」という意味です。
通常は、forループの中身を下記下して…なんて事はしません…。
そんな事をすれば、コードのメンテナンス性が下がり、バグが入りやすくなり、また、拡張性も悪くなるためです。(単純に処理回数を変更しようとするだけで、途方もない労力が必要になる)
逆に、通常の書き方をすると、関数呼び出しを使ってもそれほど処理時間に影響がないとも言えます。
個人的な経験のお話
上記までで、通常の利用をすれば、関数呼び出しのオーバーヘッドは気にするほどではないとも書きましたが、それでも…
「塵も積もれば山となる」
とも言えます。
関数の中から更に関数を呼び出し、さらにその中から関数が呼び出されてたり…、とか、ループの中に不必要な関数呼び出しが大量にあれば、やはり、処理時間が長くなります。
主にその影響が出てくるのが、画像データを自分で取り扱うような場合でしょう。(そういったモノも機会があれば紹介していければと思います)
C言語なら、マクロ関数を使うという手段もありますが(マクロ関数は、関数呼び出しではなく、マクロ定義がコード内で展開されるため)、ここでは省略します。
今回のまとめ
今回は、関数について、アセンブリコードではどのように記述され、どの様なオーバーヘッドがあるのかを確認してみました。
本編ではあまり触れませんでしたが、値渡しで関数に渡した変数をどんなに変更しても、呼び出し元の変数に影響を与えないのは、スタックの状況をみると一目瞭然ですね。
関数の利点は、同じ処理を複数個所に記述しなくて済むので、バグの減少など、コードの品質を高められる点です。
欠点としては、やはりオーバーヘッドがあるという点でしょうか?
目的とするプログラムが『実行速度最優先』という場合であれば、関数呼び出しを見直しても良いかも知れませんが、品質やメンテナンス性が著しく低下する可能性がある事を考慮する必要があります。
得られる効果に対して、失われるモノとのバランスを考えて決める必要があるでしょう。
次回の予定
次回は配列とポインタについて確認していこうと思います。
個人的には、『配列の処理は、ポインタで置き換えた方が速い』と思っているのですが(経験的に)、それを確認していこうと思います。
| 前の記事 | 次の記事 |
|---|---|
| No.03:アセンブリコードの確認 | No.05:配列とポインタ |