
使用ツール:Visual Studio Community 2019
使用言語 :C言語
TIPS(C)
今回はいくつかC言語(Visual C)につてのTIPSを紹介していきたいと思います。
コードの高速化
最適化オプション(O2)による高速化
これまでコンパイル後のアセンブリコードを確認して、ニモニックレベルでどのような処理が行われているかを確認してきました。
しかし、通常は開発時はDEBUGモード(最適化なし)、リリース時はRELEASEモード(最適化あり)でコンパイルしていて、RELEASEモード(最適化あり)でコンパイルすると処理が速くなる実感を持っている人もいるかも知れません。
最適化の有り無しでコンパイル結果がどのように変わるか、以下のサンプルコードで確認してみます。
#include <stdio.h>
// メイン関数
void main()
{
int a = 10;
int b[] = {1,2,3,4,5,6,7,8,9,10};
int sum = 0;
for(int i = 0; i < 10; i++)
{
sum += b[i];
}
printf("sum = %d\n", sum);
}このコードでは配列b[]の内容を合計してその結果を出力します。また、利用しない変数aもあります。
このコードを最適化なしでコンパイル[cl.exe /FA sample_008_1.c]し、アセンブリコードを見てみると以下の様になります。
_TEXT SEGMENT _a$ = -56 ; size = 4 _sum$ = -52 ; size = 4 _i$1 = -48 ; size = 4 _b$ = -44 ; size = 40 __$ArrayPad$ = -4 ; size = 4 _main PROC ; File C:\Test\LLP_008\sample_008_1.c ; Line 5 push ebp mov ebp, esp sub esp, 56 ; 00000038H mov eax, DWORD PTR ___security_cookie xor eax, ebp mov DWORD PTR __$ArrayPad$[ebp], eax ; Line 6 mov DWORD PTR _a$[ebp], 10 ; 0000000aH ; Line 7 mov DWORD PTR _b$[ebp], 1 mov DWORD PTR _b$[ebp+4], 2 mov DWORD PTR _b$[ebp+8], 3 mov DWORD PTR _b$[ebp+12], 4 mov DWORD PTR _b$[ebp+16], 5 mov DWORD PTR _b$[ebp+20], 6 mov DWORD PTR _b$[ebp+24], 7 mov DWORD PTR _b$[ebp+28], 8 mov DWORD PTR _b$[ebp+32], 9 mov DWORD PTR _b$[ebp+36], 10 ; 0000000aH ; Line 9 mov DWORD PTR _sum$[ebp], 0 ; Line 11 mov DWORD PTR _i$1[ebp], 0 jmp SHORT $LN4@main $LN2@main: mov eax, DWORD PTR _i$1[ebp] add eax, 1 mov DWORD PTR _i$1[ebp], eax $LN4@main: cmp DWORD PTR _i$1[ebp], 10 ; 0000000aH jge SHORT $LN3@main ; Line 13 mov ecx, DWORD PTR _i$1[ebp] mov edx, DWORD PTR _sum$[ebp] add edx, DWORD PTR _b$[ebp+ecx*4] mov DWORD PTR _sum$[ebp], edx ; Line 14 jmp SHORT $LN2@main $LN3@main: ; Line 16 mov eax, DWORD PTR _sum$[ebp] push eax push OFFSET $SG9255 call _printf add esp, 8
最適化なしでコンパイルすると、C言語のソースコードと1対1で対応が取れるアセンブリコードが生成されています。(使わない変数aについてもスタックに領域が確保され[34行目]、初期化も行われています[49行目])
では最適化ありでコンパイル[cl.exe /FA /O2 sample_008_1.c]してみると、どの様なアセンブリコードが生成されるかを確認してみます。
_TEXT SEGMENT _main PROC ; COMDAT ; File C:\Test\LLP_008\sample_008_1.c ; Line 16 push 55 ; 00000037H push OFFSET ??_C@_09GEJEEMHD@sum?5?$DN?5?$CFd?6@ call _printf add esp, 8
さて、やたらアセンブリコードが短くなりました…。
そもそも、変数a, sum, iや配列b[]についての記述がどこにもありません…。
32~34行目はprintf関数を呼び出す部分です。32行目はprintf関数に渡す引数でsumに該当する部分ですが、ここに「55」というC言語のソースコードにはなかった値が出てきています。
実はこの値は、配列b[]の各要素の総和です。最適化指定されたコンパイラがC言語のソースの6~15行目の処理の結果を計算してしまっています。(計算できる事が前提ですが…)
元々C言語ソースの期待する実行結果は、総数55(”sum = 55″)を出力すれば良いので、計算処理は実行時に毎回行うのではなく、コンパイル時に1回行ってしまい、実行時には出力のみ行うという事を行っています。
最適化されたアセンブリコードを元にC言語を書き下せば以下の様になります。
#include <stdio.h>
void main()
{
printf("sum = %d\n", 55);
}なんだか横着なコードにも思えますが、まぁ、実行した結果は同じになりますね…。
ここまで見た様に、コンパイラの最適化(O2オプション)は以下の様な事を行います。
- 不要(使用しない)変数は無視
- コードの中で同じ結果になる部分はコンパイル時に予め計算して計算結果のみ利用
- まとめられるコードは統合
- 削除できるコードは削除
- 文字列の難読化
- など
最適化を行うと、元々のコードとはかけ離れたものになるので、デバッガを使ったデバッグが困難になるのはこのためです。
※「文字列の難読化」について、最適化をしないとC言語ソース中の文字列(”sum = %d“)は実行ファイル(EXEファイル)の中にそのまま格納されてしまうのでセキュリティ的に問題がありますが、最適化を行うと、アセンブリコードの33行目の様に文字列は暗号化され簡単には推測できなくなります。

アルゴリズムによる高速化
もし、「整数n(>0)から整数m(>n)までの総和を求める」コードを作成しなければならなくなったら、多くの人は以下の様なforループを用いたアルゴリズムに基づいたコードを思い浮かべるかと思います。
long long sum = 0;
for(long long i = n; i <= m; i++)
{
sum += i;
}
printf("%lldから%lldまでの総和:%lld\n", n, m, sum);このコードの場合、(m – n + 1)回sumの加算、iの加算、mとの比較などの処理が必要になります。
整数mが小さい値の場合はこれでも問題はありませんが、整数mの値が大きくなればなるほど処理量は増えていきます。(それでも、最近のPCは一瞬で計算は終わってしまいますが…)
整数mが大きくなっても計算量が増えない様にしようとした場合、以下の公式を用います。
整数1~Nまでの総和は、N x (N + 1) / 2
そのため、「1~mまでの総和を求め、そこから1~n-1までの総和を引く」という計算で、目的の結果が得られます。
整数n(>0)から整数m(>n)までの総和
m * (m + 1) / 2 – (n – 1) * n / 2
↓ ※式を整理すると
(m * m + m – n * n +n) / 2
C言語ソースでは以下の様になります。
long long sum = (m * m + m - n * n + n) / 2;
printf("%lldから%lldまでの総和:%lld\n", n, m, sum);このコードでは、n, mの値がどんなに大きくなっても、乗算と加算が2回、減算と除算が1回と計算回数は固定なので、処理は一瞬で終わります。
上記の様に、地道に計算を行わなくても、公式を使えば計算量を少なくする(処理時間を短縮する)事が可能になります。
公式でなくても、現在の様なパソコン(計算機)が登場してからこれまでに、処理時間短縮のために様々なアルゴリズムが開発されていますので、それを利用する事で高速化する事が出来ます。
dumpbin.exeツール
実行ファイル(EXEファイル)から様々なデータを取得できるdumpbin.exeツールを紹介します。
(コンパイラと同じく、Devloper Command Prompt上で実行できます)
逆アセンブル
dumpbin.exeを利用すれば、これまでC言語のソースコードのコンパイル時にコンパイラのFAオプションでアセンブリコードを出力していましたが、実行ファイル(EXEファイル)からアセンブリコードを確認できます。
上記で作成した「sample_008_1.exe」を逆アセンブルするには、下記の様なコマンドを実行します。
> dumpbin.exe /DISASM sample_008_1.exe実行結果がコマンドプロンプトに表示されますが、量が多いので画面が流れてしまうと思うので、リダイレクトでファイルに格納しても良いかと思います。
Microsoft (R) COFF/PE Dumper Version 14.29.30146.0
Copyright (C) Microsoft Corporation. All rights reserved.
Dump of file sample_008_1.exe
File Type: EXECUTABLE IMAGE
00401000: 55 push ebp
00401001: 8B EC mov ebp,esp
00401003: 83 EC 38 sub esp,38h
00401006: A1 10 90 41 00 mov eax,dword ptr ds:[00419010h]
0040100B: 33 C5 xor eax,ebp
0040100D: 89 45 FC mov dword ptr [ebp-4],eax
00401010: C7 45 C8 0A 00 00 mov dword ptr [ebp-38h],0Ah
00
00401017: C7 45 D4 01 00 00 mov dword ptr [ebp-2Ch],1
00
0040101E: C7 45 D8 02 00 00 mov dword ptr [ebp-28h],2
00
00401025: C7 45 DC 03 00 00 mov dword ptr [ebp-24h],3
00
0040102C: C7 45 E0 04 00 00 mov dword ptr [ebp-20h],4
0
…(略)…C言語ソースのmain関数に該当するのは9行目以降になります。
上述のアセンブリコードと比較すると、同じ内容になっているのが分かると思います。
※逆アセンブルうしたコードはコメントはなく、ラベル等は実際の値やアドレスに変換されています。
32bit向けか64bit向けかの確認
実行ファイルが32bit向けにビルドされたものか、64bit向けにビルドされたものかを確認する場合は、/HEADERSオプションを利用します。
> dumpbin.exe /HEADERS sample_008_1.exe表示される情報の中で「FILE HEADER VALUES」(最初の部分)を確認します。
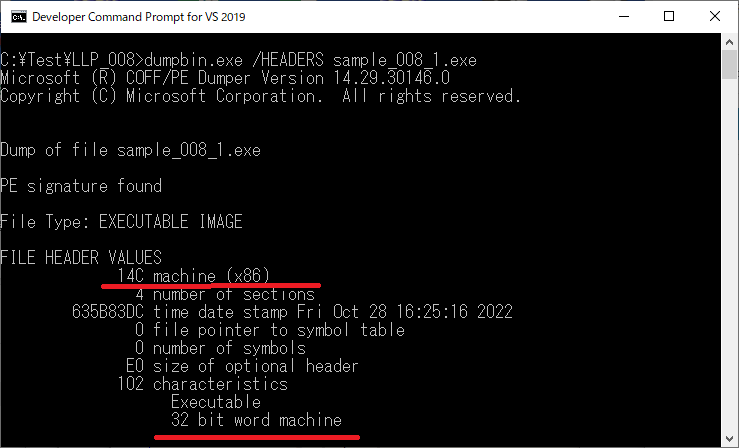
上記の様に「machine (x86)」や「32 bit word machine」と表示され、32bit向けのEXEファイルである事が分かります。
64bit向けのEXEの場合は下記の様に表示されます。
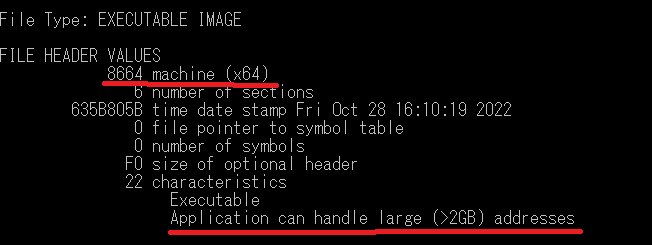
64bit向けのEXEでは、「machine (x64)」や「Application can handle large (>2GB) addresses」(アプリケーションは2GB以上の大きなアドレスを扱う事が可能)という表現が見られます。
※32bit向けでは、2GB未満までのアドレスしか扱えないという事ですね。
64bit向けEXEの作り方
これまでの記事で利用してきた「Devloper Command Prompt for VS 2019」上でcl.exeを使ってコンパイルすると、作成される実行ファイルは32bit向けEXEファイルとなります。
64bit向けのEXEファイルを作成したい場合は、スタートメニューから「x64 Native Tools Command Prompt for VS 2019」を選択して、x64専用のコマンドプロンプトを立ち上げます。
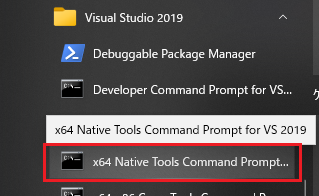
起動されるコマンドプロンプトの表示に「Environment initialized for: ‘x64’」と64bit向けのコマンドプロンプトだと分かる様に表示されます。
このプロンプト上で、「cl.exe」を使ってコンパイルすれば、作成される実行ファイルは64bit向けとなります。
32bit向け、64bit向けのコンパイル時には、型のサイズが異なる場合があるので注意が必要です。
| 型 | 32bit向け | 64bit向け |
|---|---|---|
| short | 2 byte | 2 byte |
| int | 4 byte | 4 byte |
| long | 4 byte | 4 byte |
| long long | 8 byte | 8 byte |
| float | 4 byte | 4 byte |
| double | 8 byte | 8 byte |
| size_t | 4 byte | 8 byte |
※上記の型のサイズは、Visual Cの場合の物です。他の言語ではサイズが異なる場合があるので注意してください。
次回の予定
次回からC#(シー・シャープ)についての投稿を予定しています。
これまでC言語を見てきたのは、コンパイラがリスティングの機能(x86向けアセンブリコードを出力する機能)を持っていたためです。
C#を使って、主に処理時間について見て行きたいと思っています。
| 前の記事 | 次の記事 |
|---|---|
| No.07:スタック領域とヒープ領域 | No.09:C#について |