
使用ツール:Visual Studio Community 2019
使用言語 :C言語
アセンブリコードの確認
前回(『No.02:アセンブリコードの生成』)で、C言語のソースコードからアセンブリコードを生成しました。
今回はその内容を確認していきます。
CPUとメモリの構成
アセンブリコードを確認する前に、CPUやメモリの構成を抑えておきます。
(実際には、物理メモリや論理メモリ、OSによる管理などごちゃごちゃしていますが、今回は説明に最低限必要な部分のみ抜き出しシンプルにしていますので、ご了承ください。)
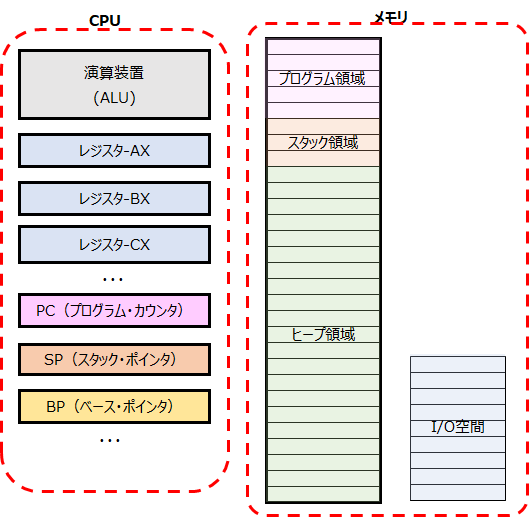
基本、どの様なプログラムも上記の様なCPU、メモリの構成上で動作します。
メモリ
メモリは複数の領域に分割されます。どの位置(アドレス)に配置されるかはPC、OS、開発言語、コンパイルのオプションなどによって変わります。
| 種類 | 説明 |
|---|---|
| プログラム領域 | 実行プログラムが配置される領域 |
| スタック領域 | LIFO(Last-In-Fast-Out)形式のバッファ領域 関数実行時のローカル変数や関数呼び出し時の各種情報を格納する |
| ヒープ領域 | コード中malloc(), new等で動的にメモリを確保する際に利用される領域 |
| I/O空間 | IOポートへアクセスするための領域 |
今回の記事で扱うのは、プログラム領域とスタック領域のみです。
CPU
CPUは、演算装置と複数の汎用レジスタから構成されます。
| 構成要素 | 説明 |
|---|---|
| 演算装置 | PC(プログラム・カウンタ)の指し示すプログラム位置の命令を実行する。 |
| レジスタ-AX | 汎用レジスタ |
| レジスタ-BX | 汎用レジスタ |
| レジスタ-CX | 汎用レジスタ |
| PC(プログラム・カウンタ) | プログラム領域の実行位置を保持する。 (命令ポインタ[IP]と呼ばれることもある) |
| SP(スタック・ポインタ) | スタック領域の現在(最新)のデータ位置(アドレス)を保持 |
| BP(ベース・ポインタ) | スタック領域でのベースアドレスを保持する。 SPはこのBPを超えてデータを取り出す事はできない。 |
『レジスタ』は32bitや64bitの情報を格納可能な高速なメモリと考えてよいかと思います。
汎用レジスタ(AX,、BX、CX…)は名前の通り、特定用途ではなく、様々な値を格納したり、読み出したり、演算装置による計算に利用されます。
ただ、通常はどのレジスタをどのように使うかが、だいたい決まっています。(なので、アセンブリコードが読みやすくなっているとも言えます)
PC(プログラム・カウンタ)は、プログラムの実行位置を示し、その位置の命令が実行されると、カウンタの値は次の実行位置になる様に更新されます。
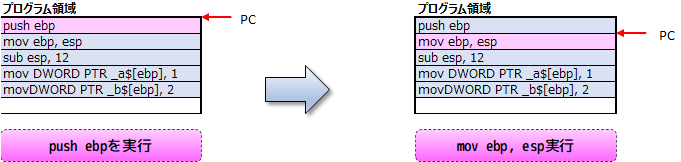
上記図では、ニーモニックがメモリ上に配置される様に記載していますが、実際には、機械語に変換されたものがメモリ上に配置されます。機械語に変換された際に、その命令に必要なバイト数は命令によって異なるため、分かりやすくするためにニーモニックで表現しています。
BP(ベース・ポインタ)は、スタック領域において、現在使用しているスタックの区切りを指定するために利用されます。

BPは現在実行中の関数のローカル変数の位置を指定するために利用されます。
SP(スタック・ポインタ)は、PUSH命令で渡された値をスタック領域のSPの指し示す位置(アドレス)に格納したり、POP命令時、スタック領域のSPの指し示す位置(アドレス)の一つ前の位置から取得したりするために利用します。
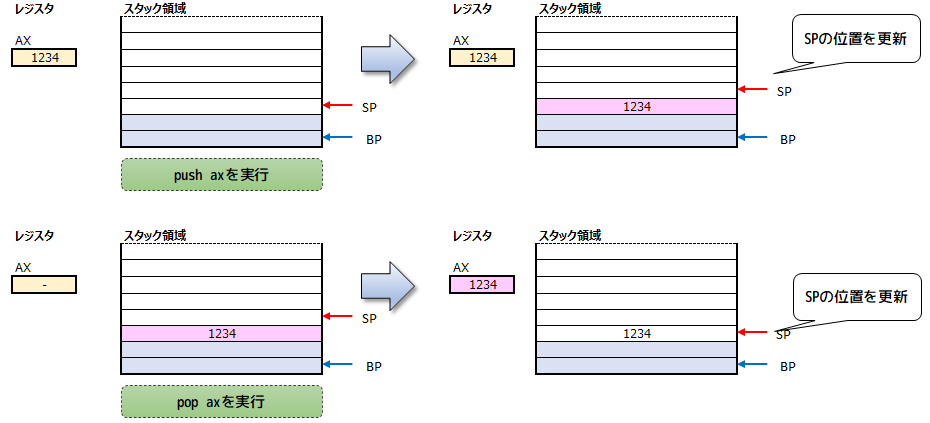
PUSH/POPする事が出来るのはレジスタの値のみです。(出し入れする値のサイズを一致させるためでしょう)
前置きが長くなりましたが、アセンブリコードを理解するのに必要なCPU/メモリ構成についての説明でした。
アセンブリコード
下記のC言語のソースコードに対応するアセンブリコードを確認していきましょう。
#include <stdio.h>
void main()
{
int a = 1; // 変数aに1を代入
int b = 2; // 変数bに2を代入
int c = a + b; // 変数cにa+bの計算結果を代入
}まず、ローカル変数a, b, cに関する記述は下記になります。
_c$ = -12 ; size = 4 _b$ = -8 ; size = 4 _a$ = -4 ; size = 4
これは、値を代入しているのではなく、BP(ベース・ポインタ)が指し示すアドレスに対する相対位置を表しています。C言語のintのサイズが4byteなので、4ずつ位置がずれています。
Cソースのmain()関数の先頭部分(3,4行目)は下記の様になります。
※「;」(セミコロン)で始まる部分はコメントになります。
※「; Line XX」のコメントは、コンパイルしたC言語ソースの該当行数を示します。
※各レジスタ名の前に「e」がついていますが、そういう物と思って読んでください。細かい説明は割愛します。
_main PROC ; File C:\Test\LLP_002\llp_001.c ; Line 4 push ebp mov ebp, esp sub esp, 12 ; 0000000cH
ここでは、BPとSPの初期設定を行っています。これが実行されるとスタック領域は下記の様になります。
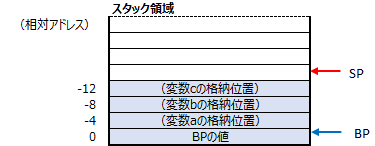
これで、変数a, b, cへアクセスできる様になりました。
int a = 1; // 変数aに1を代入 int b = 2; // 変数bに2を代入
Cソースの変数a, bの代入部分に該当するアセンブリコードは下記になります。
; Line 5 mov DWORD PTR _a$[ebp], 1 ; Line 6 mov DWORD PTR _b$[ebp], 2
「mov」コマンドを利用して、それぞれの変数へ値を格納しています。
※movコマンドは指定箇所1から(もしくは直値を)、指定箇所2へ値をコピーするコマンドです。
BPに対する相対アドレス(”_a$[ebp]”)と、アクセスサイズ(”DWORD PTR”)を指定してアクセスしています。
このコマンドを実行するとスタック領域は下記のような状態になります。
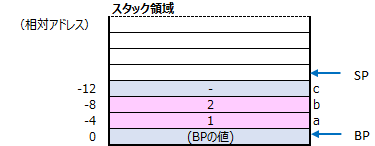
int c = a + b; // 変数cにa+bの計算結果を代入
Cソースで変数aと変数bの値を足して、変数cに代入する部分に該当するアセンブリコードは下記になります。
; Line 8 mov eax, DWORD PTR _a$[ebp] add eax, DWORD PTR _b$[ebp] mov DWORD PTR _c$[ebp], eax
29行目では、「mov」コマンドでスタック領域の変数aのアドレスから変数aの値を取得し、レジスタAXに格納しています。
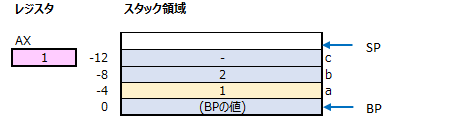
30行目では、「add」コマンドで、現在レジスタAXに格納されている値に、スタック領域の変数bの値を加算して、結果をレジスタAXに格納しています。
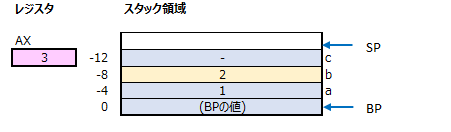
※addコマンドは、指定の2つの場所(レジスタやメモリ上のアドレス)の値を加算して、結果をAXレジスタに格納するコマンドです。
31行目では、「mov」コマンドで、レジスタAXに格納されている加算結果の値を、スタック領域の変数cのアドレスへ格納しています。
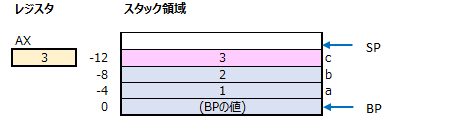
「c=a+b」という処理は、アセンブリコードでは、3命令で実現される事が分かります。
}
main()関数の最後の部分は、終了処理が行われます。
(始まり部分と同じで、定型句的な処理になっています。)
; Line 9 xor eax, eax mov esp, ebp pop ebp ret 0 _main ENDP
33行目はAXレジスタのXOR演算を行い結果をAXレジスタに格納しています。同じAXレジスタの値をXOR(排他的論理和)をしているので、必ず0になりますので、AXレジスタを0にする処理になります。
34, 35行目は、main()関数が呼ばれた時点のSP、BPの値を復元する処理になります。(main()関数の入り口の処理の逆を行っています)
36行目は、関数呼び出し元へ戻るための「ret」コマンドです。(retコマンドの後ろの数字「0」は戻り値ではなく、解放すべきスタックのサイズを示しています。push/popの対応が取れていれば、通常は「0」でしょう)
今回のまとめ
今回は簡単なC言語のソースコードから作成されるアセンブリコードの動きを見てきました。
代入や簡単な四則演算であれば、アセンブリコードと言っても、それほど複雑ではなかったと思います。
次回の予定
次回は、関数呼び出しについて見て行こうと思います。
「関数を呼び出すのはコストが大きい」と言われていた(最近はCPUの性能が格段に上がったので、あまり気にされなくなっていますが…)理由とかにも触れたいと思います。
| 前の記事 | 次の記事 |
|---|---|
| No.02:アセンブリコードの作成 | No.04:関数について |